2017年2月12日
ビッグデータとは何か?PartⅠ
量と頻度と多様性の膨大なデータと処理システム
おはようございます。
今回は「ビッグデータとは何か?」と題して、昨今業界の必須の用語であるビッグデータのあらましに関する記事を掲載します。
記事は日本を代表する企業、日立様のホームページからの記事です。さすがに日立様だけあって、非常に簡潔にわかりやすく、ビッグデータというものがどういうものかを順を追って話を進めている、読みやすい記事です。
これまで、フィンテックやシェア、自動運転車やウーバー、エコー、Amazon Goといった、最新のIT技術を活用したサービスや製品、ビジネスモデルをご紹介してきました。しかし、それらのサービスや製品の根底にあるのはやはりクラウドと一体になったビッグデータという存在です。
このビッグデータという響きに拒絶反応を起こす方もたくさんいらっしゃいますし、またそんなものはとっくに知っているという方もいらっしゃることだと思います。しかし、今から10年ほど前にクラウドビジネスが始まり、それとともに集積されたビッグデータはそれまでの膨大な人力で集められた、体系的なデータとは異なっています。
端的に言えば、それまではエクセルで統計をとれるような、組織的にまとまった数量的データです。これを「構造的データ」といいます。しかし、ビッグデータはそういった従来のデータも含みながら、インターネットはスマホ、SNSの発展に伴い膨大に集積し始められた量や更新の速さ、多様性に富む種類のデータといった「非構造的データ」を活用していく大きな取り組みです。
ビッグデータという言葉はもう各方面でに広がっていますが、まだまだその本質を完全につかめている人や業界はいないといっていいでしょう。そして、それを本格的に活用し、ビジネスに何らかの利益をもたらしている企業はまだまだ少ないといった状況です。
そこで、今回から3回に分けて、ビッグデータの根本的な知識を端的に述べた記事を掲載していきたいと思います。
コラム: ビッグデータへの道
第1回「ビッグデータとは」
ビッグデータの利活用がこれからの世の中に起こすイノベーションを明らかにします。
http://www.hitachi.co.jp/products/it/bigdata/column/column01.html
ここ数年、企業IT関連で最も注目されてきたキーワードと言えば「クラウド」を思い浮かべる方が多いと思います。しかし、2011年から「ビッグデータ」が新たなキーワードとして急速に注目され始めました。
これまでも企業はデータや情報をビジネスに役立てるために様々なITを利用してきました。多くの企業で、DWH(データウェアハウス)やBI(ビジネス・インテリジェンス)ツールといった製品または顧客管理や販売管理などのアプリケーションをすでに利用していると思います。
では、「ビッグデータ」なぜ注目されているのでしょうか。「ビッグデータ」はこれまでのものと何が違うのでしょうか。本コラムではビッグデータに関する雑誌寄稿 ・調査で定評のある調査会社、株式会社アイ・ティ・アールの生熊清司氏にご協力をいただき、3回のシリーズで「ビッグデータ」について考えていきたいと思います。
「ビッグデータとは?」
「ビッグデータ」はそのままの意味で解釈すれば巨大なデータとなります。現在、日本の企業の大規模DWHの容量は、数テラバイトの規模が多いのですが、例えば、1,000テラバイト(1ペタバイト)の規模のシステムを「ビッグデータ」と言うのでしょうか。
もう1つ「ビッグデータ」と言えばよくFacebookなどのソーシャル・ネットワークのことが引き合いに出されます。確かにFacebookの会員数は8億人を超えたと言われており、1日に10テラバイトのデータを処理していると言われています。
そして、これらのソーシャル・メディアはRDBMS(リレーショナル・データベース)でなく、NoSQLという別のデータ管理ソフトウェアを利用しています。では「ビッグデータ」はNoSQLのシステムということでしょうか。
この2つから考えると「ビッグデータ」とは、「1ペタバイトのような非常に大量データをNoSQLを利用して処理するシステム」という答えになります。さて、この答は正解でしょうか。答えは△だと考えます。正しいですが、「ビッグデータ」の全てを表してはいません。「ビッグデータ」が表す意味はもう少し複雑なものだと考えています。
なぜかと言えば、RDBMSを利用して大量のデータを利用している企業は世界にすでに存在しているからです。
例えば、Bank of Americaでは1.5ペタバイト以上のDWHを持ち、世界的なスーパーマーケットチェーンであるウォルマート・ストアーズでは2.5ペタバイト以上、さらにインターネットのオークション・サイトであるeBayでは6ペタバイト以上のデータを格納したDWHが稼働しているそうです。ですから、単純のペタバイトなら「ビッグデータ」ではないのです。
ちなみに、このような巨大なDWHシステムはEDW(エンタープライズ・データウェアハウス)と呼ばれており、そのデータベースはVLDB(Very Large Databese)と呼ばれてきました。
また、確かに、NoSQLはRDBMSに比べて、スケールアップ(スケールアップとは処理性能を上げるためにサーバやストレージの台数を増やして、処理性能を向上させること)に向いていると言われています。しかし、だからといって、RDBMSが不要となるわけではありません。NoSQLは文書や画像などの非構造化データの処理には適していますが、数値などの構造化データ、それもデータの正確性を重要視するような処理には向いていないのです。
実際、Facebookでもすべての処理をNoSQLで行っているわけでなく、RDBMSも利用しています。つまり。データの種類と必要な処理に応じて、RDBMSとNoSQLを使い分けているのです。
編集部からのコメントです。
専門的な言葉が多く、わかりにくくなってきたのでここでまとめておきます。
まず、これまでも「ビッグ」なデータは存在し、それはDWH(データウェアハウス)などといったアプリケーションで行われていましたが、それらはRDBMS(リレーショナル・データベース)というソフトウェアによって、テラバイト(1,024ギガバイト、つまり1,000ギガだと考えてよい)レベルのデータの集積を扱っていたということです。
しかし、RDBMSは数値などの「構造化データ」を扱うのみで、データの正確性を重要視するきまりきった提携のデータ処理を行っていました。
それに対してNoSQLというデータ管理ソフトウェアは、テラバイトのさらに1000倍のペタバイト(1ペタバイトは1,024テラバイト)という単位で情報を取り扱い、さらに、SNSやネット上での大量で不規則な情報である文書や画像などの「非構造化データの処理」をこちらで行うようになったのです。
もちろん「構造化データ」処理が得意なRDBMSでもペタバイトレベルの処理は行えるため、「RDBMSとNoSQLの両方のソフトウェアを駆使して、「構造化データ」と「非構造化データ」の両方をペタバイトレベルで処理する」というのがビッグデータのとりあえずの定義といえるでしょう。
つまり、数字などの決まったデータと雑然としたデータを、それぞれに適したソフトウェアで交互にペタバイトレベルで処理するということです。
(記事の続き)
では、「ビッグデータ」とは何なのでしょうか。残念ながら共通定義はまだ定まってはいません。1つの定義としては、「ビッグデータとはインターネットの普及とIT技術の進化によって生まれた、これまで企業が扱ってきた以上に、より大容量かつ多様なデータを扱う新たな仕組みを表すもので、その特性は量、頻度(更新速度)、多様性(データの種類)によって表される。」と考えます。
これでは、分かり難いと思われる方もいらっしゃると思うので、この定義について説明を続けます。
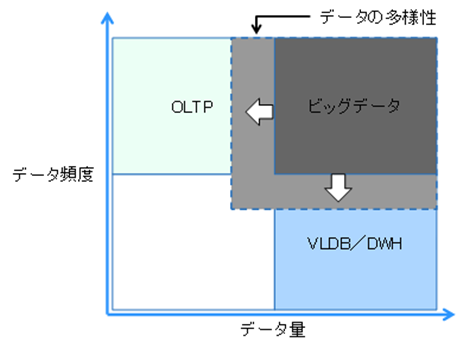
図1:ビッグデータの特性
図1は、定義に出てきた特性を表しています。「ビッグデータ」はこれまでのDWHやOLTPといったシステムにくらべ、以下の3つの部分に違いがあります。
1つめはデータ量が多いということ、2つめはデータの種類が多いということ、そして3つ目はデータの変化する頻度が多いということです。そして、これらの条件が重なることで、従来のシステムでは取り扱うことが困難であったデータとそれを扱うためのシステムのことを「ビッグデータ」と呼びます。
特に、ビッグデータの特徴は、量だけでなく、扱うデータの種類が多いことにあります。扱うデータには、構造化データと呼ばれる、会計システムなどの基幹システムから発せられる数値や文字列といったデータだけでなく、非構造化データと呼ばれる、文章、音声、動画といったマルチメディア・データなどのデータが含まれます。
さらに、電子メールのデータやXMLデータなどの半構造化データ、さらに、各種センサーや機器から発せられるデータや通信ログように頻度が非常に多いようなデータも含まれます。さらに、これらのデータには社内だけでなく、インターネット上の社外にある場合も多くあります。
この取り扱うデータの種類の差が、従来のシステムとビッグデータを区別するヒントとなると思います。ビッグデータの活用を先導している企業の多くはGoogle やFacebookといったWebサービス事業者です。そして彼らのデータ活用は、従来の売り上げデータや顧客データのような社内に存在するデータではなく、Web上にある文章や画像といったデータが中心となっています。
さらに、これまで企業の多くはデータ活用をたとえ顧客データであっても、活用目的は個々の顧客の属性ではなく、集計することによって得られる傾向情報が中心でした。
しかし、これらのWebサービス事業者では、顧客の個々の属性を捉え、Amazonのようなリコメンデーションのように細分化された情報を利用しています。そして、大きく異なるのは、データ処理に対する精度よりもスピードが重視していることです。
図2は、これまでのシステムとビッグデータでのデータに対する考え方の違いをまとめてみました。図の左側のようなデータに対する考え方であればRDBMSが向いており、左側のような場合はNoSQLが向いているのです。そして、「ビッグデータ」は右側のような考え方に基づいたデータ処理と言えます。
従来のDWHは大容量であっても、構造化データ中心で、データ更新の頻度も月単位など変化頻度はそれほど高くありませんでした。したがって、大容量+非構造化データ+高頻度という新たな組み合わせに対応するシステムとして「ビッグデータ」が注目されるようになったのです。

図2:ビッグデータのデータに対する考え方
まとめ
「ビッグデータとはインターネットの普及とIT技術の進化によって生まれた、これまで企業が扱ってきた以上に、より大容量かつ多様なデータを扱う新たな仕組みを表すもので、その特性は量、頻度(更新速度)、多様性(データの種類)によって表される。」
注意点
・大きなデータだからといってすべてが「ビッグデータ」ではない。
・どんな場合でもNoSQLで処理するべきではなく、RDBMSとNoSQLは使い分ける。
・ビッグデータとこれまでのシステムとの大きな違いは扱うデータの種類にある。
編集部からのコメントです。
ビッグデータといった場合、現在の日本での認識は「ものすごく膨大な大きさと数のデータ」というものです。まだまだその本質をとらえ切れてはいません。この記事で大事なことは、「非構造化データ」ということです。単に量が多い、つまりペタバイトレベルの情報量というのではなく、いわゆるネットやSNS上の「ライフログ」というものをはじめとした多様で、スピードと変化があり、頻度の高い雑然としたとりとめのない情報を扱うことがビッグデータなのです。
こうした非構造化データをフルに活用して、金融業界に革命を起こしたのが「フィンテック」のスタートアップ企業であり、P2PやPSSといったビジネスモデルです。
クラウドが約10年前から始まり、それに伴ったビッグデータの扱い問題が出てきました。これをビジネスチャンスにつなげることが、これからの企業の生き筋ですが、必ずしも大きなデータを手に入れて処理すればいいというものではありません。
どのような目的で、いかなる市場でどのようにビッグデータを活用するかは、企業によって千差万別です。またそのためには、自社のデータベース構築とAI=ディープラーニングを活用した解析が必要になると思います。
上記の記事にある量、頻度(更新速度)、多様性(データの種類)、RDBMSとNoSQLといった言葉まずはビッグデータの基礎情報です。IT系の新しい試みには、どうしても二の足を踏む傾向がありますが、まだまだどこもはっきりとした活用とビジネスモデルを構築したとは言えない状況です。
ですから、まずはその基本的知識を知ることが、今後の企業やビジネスの成功につながる一歩です。当社も来るべき「ヘルステック」という医療IT革命の潮流に遅れることなく備えていかなくてはなりません。
企業や個人、ビジネスやサービス同士の「エコシステム」構築もそのための一つの方法です。ですから、将来を見据えて当社は情報を発信し続けます。また何らかの情報や質問がございましたら、どのような些細なことでも当社のメールアドレスがツイッターまでお寄せください。
メールアドレス: info@noteware.com
ツイッター: @noteware_info